

什么是Pandas?
Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了 高级数据结构 和 数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
-
一个强大的分析和操作大型结构化数据集所需的工具集
-
基础是NumPy,提供了高性能矩阵的运算
-
提供了大量能够快速便捷地处理数据的函数和方法
-
应用于数据挖掘,数据分析
-
提供数据清洗功能
-
Series和DataFrame中的索引都是Index对象,索引对象不可变,保证了数据的安全
- Index对象种类:Index,索引;Int64Index,整数索引;MultiIndex,层级索引;DatetimeIndex,时间戳类型
Pandas有两个最主要也是最重要的数据结构: Series 和 DataFrame
import pandas as pd # 导包
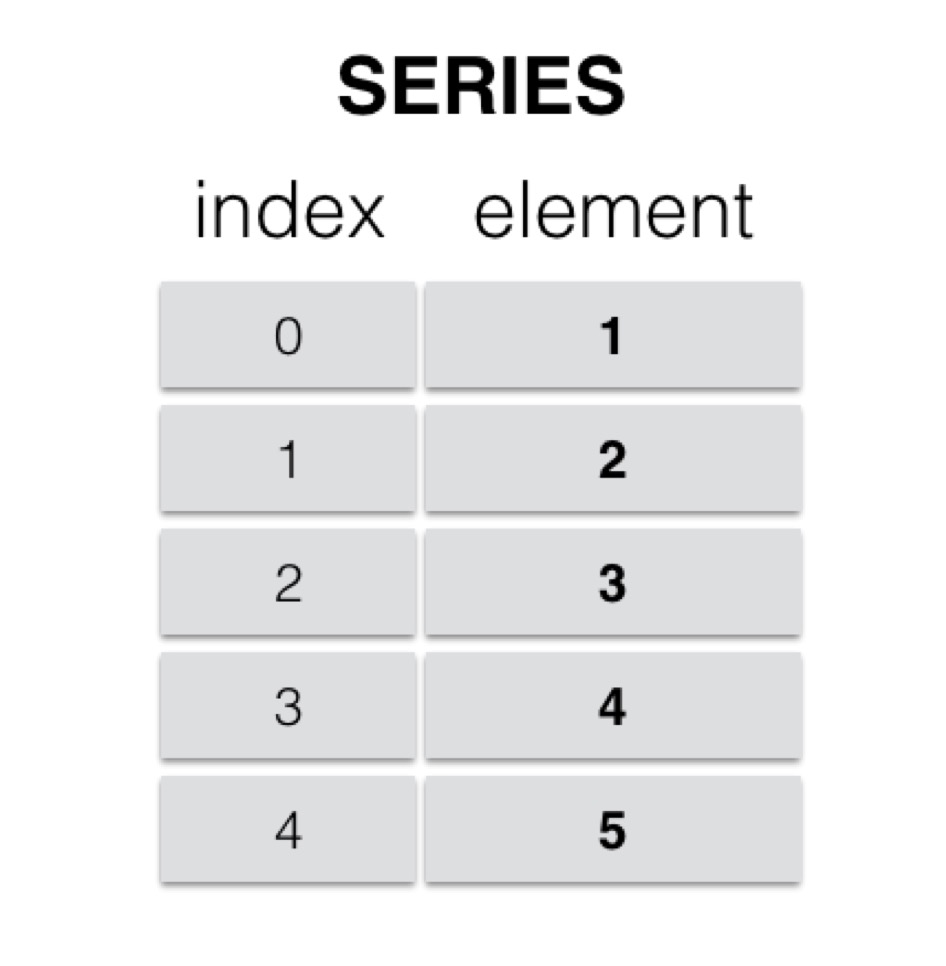
Series
Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成。
- 类似一维数组的对象
-
由数据和索引组成
- 索引(index)在左,数据(values)在右
- 索引是自动创建的
1. Series的创建
| 操作 | 代码实现 | 返回值 | 说明 |
|---|---|---|---|
|
通过list构建Series |
pd.Series(range(10)) | 新Series | 自动生成索引 |
| pd.Series(range(3), index = ['a', 'b', 'c']) | 新Series | 自定义索引 | |
|
通过dict构建Series |
pd.Series(dict) | 新Series | dict的key为索引,value为元素 |
2. Series的相关操作
| 操作 | 代码实现 | 返回值 | 说明 | |
| 获取前n行数据 | series.head(3) | 新Series | 获取前三行,默认获取前五行 | |
| 获取后n行数据 | series.tail(3) | 新Series | 获取后三行,默认获取后五行 | |
| 获取index | series.index | RangeIndex | 获取index | |
| 获取values | series.values | ndarray一维数组 | 获取所有values | |
| 运算 | series * 2 | 新Series | 索引与数据的对应关系不被运算结果影响 | |
| series > 15 | 新Series(bool) | |||
| name属性 | 对象名 | series.name | 新Series | |
| 对象索引名 | series.index.name | 新Series | ||
| 利用index取值 |
series[index] series['b'] |
对应的value值 | ||
| 利用index切片 |
series[2:4] series['b':'d'] |
新Series | 按索引名切片操作时,是包含终止索引的 | |
| 不连续索引 |
series[[0,2,4]] series[['b','d']] |
新Series | 注意是双层中括号[[…,…,…,]] | |
| 布尔索引 |
series1 = series > 2 series2[series1] |
新Series | ||
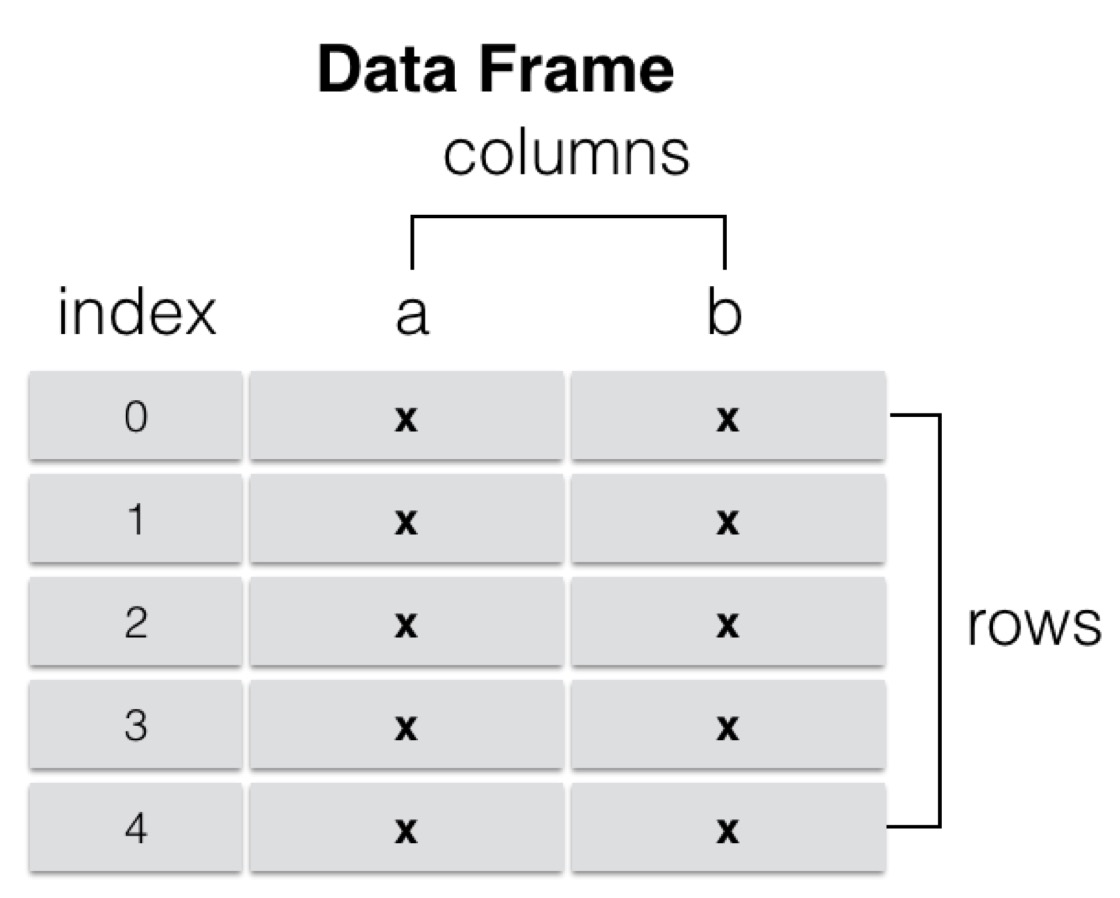
DataFrame(Series容器)
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,它可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
- 类似多维数组/表格数据 (如,excel, R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
1. DataFrame的创建
| 操作 | 代码实现 | 返回值 | 说明 |
|---|---|---|---|
|
通过ndarray构建DataFrame |
pd.DataFrame(array) pd.DataFrame(np.random.randn(3,4), columns = ['a', 'b', 'c','d']) |
新DataFrame |
通过多维数组(二维)构建DataFrame,自动生成行索引和列标签(列索引) columns 指定列索引名 |
|
通过dict构建DataFrame |
pd.DataFrame(dict) | 新DataFrame | dict的key为列标签,value为元素,自动生成行索引 |
|
dict = {'A': 1, 'B': pd.Timestamp('20190616'), 'C': pd.Series(1, index=list(range(4)),dtype='float32'), 'D': np.array([3] * 4,dtype='int32'), 'E': ["Python","Java","C++","C"], 'F': 'tiger' } |
2. DataFrame的相关操作
| 操作 | 代码实现 | 返回值 | 说明 |
| 获取前n行 | dataframe.head(3) | 新DataFrame | 获取前三行,默认获取前五行 |
| 获取后n行 | dataframe.tail(3) | 新DataFrame | 获取后三行,默认获取后五行 |
|
shape |
dataframe.shape | 元组 | 返回dataframe形状 |
| 获取index | dataframe.index | RangeIndex | 获取index |
|
columns |
dataframe.columns | RangeIndex | DataFrame的列索引列表 |
| 获取values | dataframe.values | ndarray二维数组 | 获取所有values |
| 获取列数据 | dataframe['A'] <=> dataframe.A | 新Series | 通过列索引获取列数据 |
| dataframe[['A']] | 新DataFrame(只有一列) | 注意是双层中括号[[…,…,…,]] | |
| 增加列数据 |
dataframe['G'] = series dataframe['G'] = dataframe['A'] + 4 |
新DataFrame | 类似Python的dict添加key-value |
| 删除列数据 | del(dataframe['G']) | None | |
| 不连续索引 | dataframe[['a','c']] | 新DataFrame | 注意是双层中括号[[…,…,…,]] |