

Spark Streaming属于Spark的核心api,它支持高吞吐量、支持容错的实时流数据处理。
它可以接受来自Kafka, Flume, Twitter, ZeroMQ和TCP Socket的数据源,使用简单的api函数比如 map, reduce, join, window等操作,还可以直接使用内置的机器学习算法、图算法包来处理数据。

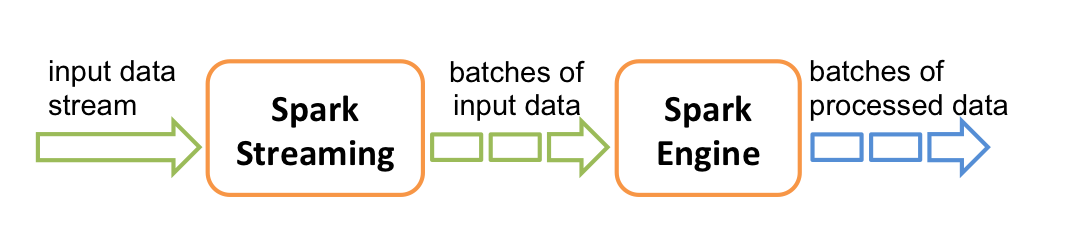
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
Discretized Stream 也叫 DStream 是 Spark Streaming 对于持续数据流的一种基本抽象,在内部实现上,DStream 会被表示成一系列连续的 RDD(弹性分布式数据集),每一个 RDD 都代表一定时间间隔内到达的数据。所以在对 DStream 进行操作时,会被 Spark Stream 引擎转化成对底层 RDD 的操作。对 Dstream 的操作类型有:
- Transformations: 类似于对 RDD 的操作,Spark Streaming 提供了一系列的转换操作去支持对 DStream 的修改。如 map,union,filter,transform 等
- Window Operations: 窗口操作支持通过设置窗口长度和滑动间隔的方式操作数据。常用的操作有 reduceByWindow,reduceByKeyAndWindow,window 等
- Output Operations: 输出操作允许将 DStream 数据推送到其他外部系统或存储平台, 如 HDFS, Database 等,类似于 RDD 的 Action 操作,Output 操作也会实际上触发对 DStream 的转换操作。常用的操作有 print,saveAsTextFiles,saveAsHadoopFiles, foreachRDD 等。