

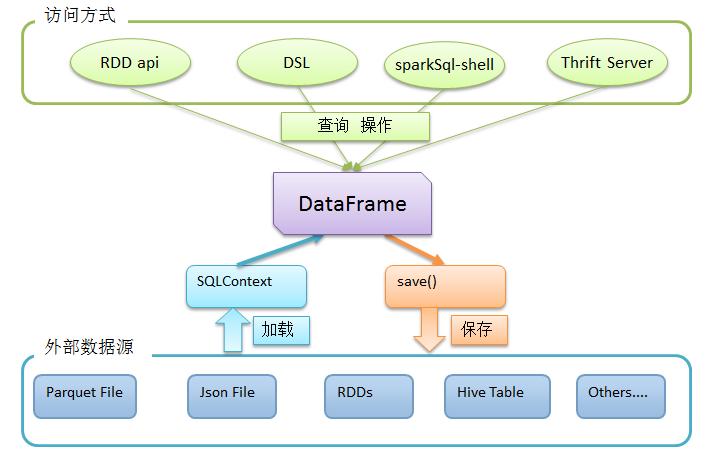
1、Spark SQL 是一个用来处理结构化数据的spark组件。它提供了一个叫做DataFrames的可编程抽象数据模型,并且可被视为一个分布式的SQL查询引擎。DataFrame是由“命名列”(类似关系表的字段定义)所组织起来的一个分布式数据集合。你可以把它看成是一个关系型数据库的表。
DataFrame可以通过多种来源创建:结构化数据文件,hive的表,外部数据库,或者RDDs,
Spark SQL 的功能是通过 SQLContext 类来使用的,而创建 SQLContext 是通过 SparkContext 创建的。可以使用SQLContext 或 RDD 来创建 DataFrames
2、 SparkSQL引入了一种新的RDD——SchemaRDD, SchemaRDD很象传统数据库中的表, SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
- 通过定义case class,使用反射推断Schema(case class方式)
- 通过可编程接口,定义Schema,并应用到RDD上(applySchema 方式)
前者使用简单、代码简洁,适用于已知Schema的源数据上;后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
对于case class方式,首先要定义case class,在RDD的transform过程中使用case class可以隐式转化成SchemaRDD,然后再使用registerTempTable注册成表。注册成表后就可以在sqlContext对表进行 操作,如select 、insert、join等
- 从源RDD创建rowRDD
- 创建与rowRDD匹配的Schema
- 将Schema通过applySchema应用到rowRDD
3、Spark SQL如何使用
首先,利用sqlContext从外部数据源加载数据为DataFrame
然后,利用DataFrame上丰富的api进行查询、转换
最后,将结果进行展现或存储为各种外部数据形式
如图所示:
//示例源文件
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
//1导入数据源
val df = sqlContext.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
//// df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
df.show() // 输出数据源内容
//// +----+-------+
//// | age| name|
//// +----+-------+
//// |null|Michael|
//// | 30| Andy|
//// | 19| Justin|
//// +----+-------+
//-----DataFrames 处理结构化数据的一些基本操作
df.select("name").show() // 只显示 "name" 列
//// +-------+
//// | name|
//// +-------+
//// |Michael|
//// | Andy|
//// | Justin|
//// +-------+
df.select(df("name"), df("age") + 1).show() // 将 "age" 加 1
//// +-------+---------+
//// | name|(age + 1)|
//// +-------+---------+
//// |Michael| null|
//// | Andy| 31|
//// | Justin| 20|
//// +-------+---------+
df.filter(df("age") > 21).show() # 条件语句
//// +---+----+
//// |age|name|
//// +---+----+
//// | 30|Andy|
//// +---+----+
df.groupBy("age").count().show() // groupBy 操作
//// +----+-----+
//// | age|count|
//// +----+-----+
//// |null| 1|
//// | 19| 1|
//// | 30| 1|
//// +----+-----+
//-------使用 SQL 语句来进行操作---
df.registerTempTable("people") // 将 DataFrame 注册为临时表 people
val result = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19") // 执行 SQL 查询
result.show() // 输出结果
//// +------+---+
//// | name|age|
//// +------+---+
//// |Justin| 19|
//// +------+---+
4、与Hive结合
spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然后在spark引擎中进行sql统计分析,效率高于hive, 配置如下:
将 $HIVE_HOME/conf/hive-site.xml copy或者软链 到 $SPARK_HOME/conf/ 将 $HIVE_HOME/conf/core-site.xml copy或者软链 到 $SPARK_HOME/conf/ 将 $HIVE_HOME/conf/hdfs-site.xml copy或者软链 到 $SPARK_HOME/conf/
运行:
$ ./bin/spark-sql -master spark://master:7077 --jars /data/mylib/mysql-connector-java-5.1.12.jar #使用spark-sql
spark-sql> show tables;
default
$ ./bin/spark-shell -master spark://master:7077 --jars /data/mylib/mysql-connector-java-5.1.12.jar #使用spark-shell
scala> sqlContext.sql("show tables").collect().foreach(println)
default
Spark sql类似于hive,可以支持sql语法来对海量数据进行分析查询,跟hive不同的是,hive执行sql任务的底层运算引擎采用mapreduce运算框架,而sparksql执行sql任务的运算引擎是spark core,从而充分利用spark内存计算及DAG模型的优势,大幅提升海量数据的分析查询速度
5 使用Scala编写,并提交运行
/*SparkSqlDemo.scala*/
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
//define case class
case class Person(name:String,age:Int)
object SparkSqlDemo {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Simple SparkSqlDemo")
val sc = new SparkContext(conf)
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
//person.txt 格式为
/*zhangsan,14
lisi,27
wangwu,31
*/
//Convert user data RDD to a DataFrame and register it as a temp table
//// 用数据集文本文件创建一个Customer对象的DataFrame
val dfpeople=sc.textFile("hdfs://hd1:9000/test/person.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt)).toDF()
// 将DataFrame注册为一个表
dfpeople.registerTempTable("tempTable")
// 显示DataFrame的内容
dfpeople.show()
// 打印DF模式
dfpeople.printSchema()
// 选择客户名称列
dfpeople.select("name").show()
// 选择客户名称和age列
dfpeople.select("name", "age").show()
// 根据age选择客户
//dfpeople.filter(dfCustomers("age").equalTo(11)).show()
// 根据age统计客户数量
//dfCustomers.groupBy("age").count().show()
var result = sqlContext.sql("SELECT * FROM tempTable")
result.collect().foreach(println)
}
}
提交编译
注意Spark内嵌Scala的版本,和Scala的版本,最好保持一样,否则会出错。
$ scalac -classpath $CLASSPATH:/data/app/spark-1.5.2/lib/*:/data/app/scala-2.10.4/lib/* SparkSqlDemo.scala
打包
jar -cvf sql.jar SparkSqlDemo*.class Person*
执行程序
$ data/app/spark-1.5.2/bin/spark-submit --class SparkSqlDemo --master spark://hd1:7077 sql.jar