Apache Kafka可以帮助你解决在发布/订阅架构中遇到消费数百万消息的问题。
Kafka是一个实时消息传输的解决方案,可处理大量实时信息,并把这些信息快速路由到各种消费者。Kafka提供了信息生产者和消费者之间的无缝集成,无需对生产者的信息进行阻塞,也无需告诉生产者那些消费者的位置。
Apache Kafka是一个开源、分布式的消息发布/订阅系统,其主要设计特性如下:
1)消息持久化
要从大数据中获取真正的价值,那么不能丢失任何信息。Apache Kafka设计上是时间复杂度O(1)的磁盘结构,它提供了常量时间的性能,即使是存储海量的信息(TB级)。
2)高吞吐
记住大数据,Kafka的设计是工作在标准硬件之上,支持每秒数百万的消息。
3)分布式
Kafka明确支持在Kafka服务器上的消息分区,以及在消费机器集群上的分发消费,维护每个分区的排序语义。
4)多客户端支持
Kafka系统支持与来自不同平台(如java、.NET、PHP、Ruby或Python等)的客户端相集成。
5)实时
生产者线程产生的消息对消费者线程应该立即可见,此特性对基于事件的系统(比如CEP系统)是至关重要的。
注:CEP即Complex Event Processing,复杂事件处理。
Apache Kafka提供了一个实时的发布/订阅解决方案,它客服了消费实时大数据的挑战,这些数据量可能在数量级的增长、真实的数据。Kafka还支持在Hadoop系统上做并行数据载入。
二. 几个基本概念:
Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
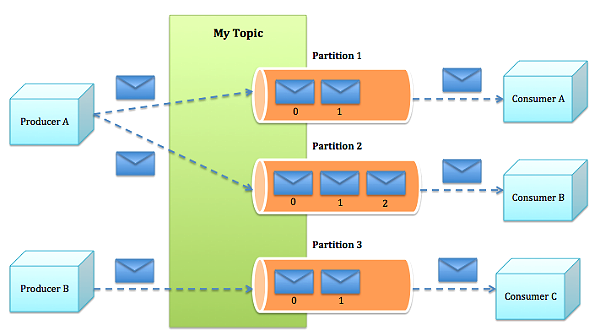
Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
Broker:缓存代理,Kafa集群中的一台或多台服务器统称为broker。
下面的视图显示了Apache Kafka消息系统支持的一个典型的大数据汇聚和分析的场景:
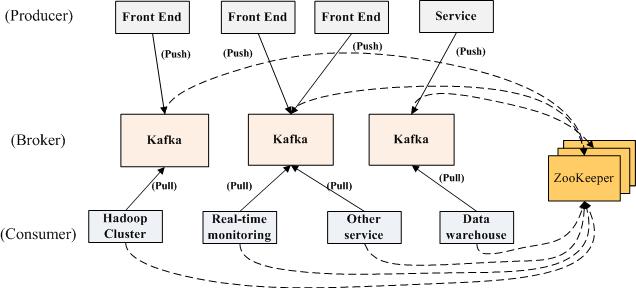
在生产者端,有数种不同的生产者:
1)前端Web应用产生的应用日志
2)生产者代理产生的Web分析日志
3)生产者适配器产生的传输日志
4)生产者服务产生的调用跟踪日志
在消费者端,有数种不同的消费者:
1)离线消费者:消费消息并在Hadoop或传统的数据仓库中存储消息用于离线分析
2)近乎实时的消费者:消费消息并在任意NoSQL数据库(如HBase或Cassandra)中存储消息用于近实时分析
3)实时消费者:在内存数据库中过滤消息,并在相关的群组中触发警告事件
Kafka集群保持所有的消息,直到它们过期, 无论消息是否被消费了。
每一个分区(partition)都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
Kafka可以用于:
消息系统, 例如ActiveMQ 和 RabbitMQ.
站点的用户活动追踪。 用来记录用户的页面浏览,搜索,点击等。
操作审计。 用户/管理员的网站操作的监控。
日志聚合。收集数据,集中处理。
流处理。
Commit Log
三. offset管理
auto.commit.enable 默认为true, 也就是offset定时保存到zookeeper里,下次读取的时候,从上次commit的offset读取。
auto.commit.interval.ms为多久提交一次offset, 默认1分钟
auto.offset.reset 默认为largest
此配置参数表示当此groupId下的消费者,在ZK中没有offset值时(比如新的groupId,或者是zk数据被清空),consumer应该从哪个offset开始消费.
largest表示接受接收最大的offset(即最新消息),smallest表示最小offset,即从topic的开始位置消费所有消息.
四. consumer和partition
-
如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数
-
如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀
-
如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
-
增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
-
High-level接口中获取不到数据的时候是会block的
负载低的情况下可以每个线程消费多个partition。但负载高的情况下,Consumer 线程数最好和Partition数量保持一致。如果还是消费不过来,应该再开 Consumer 进程,进程内线程数同样和分区数一致。
kafka安装配置参考:
1、下载安装KAFKA
$ wget http://mirrors.cnnic.cn/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
解压并进入目录:
$ tar -xzvf kafka_2.11-0.8.2.1.tgz
$ cd kafka_2.11-0.8.2.1
运行 kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka 提供的脚本启动一个 zookeeper 实例
启动Kafka server:
$ bin/kafka-server-start.sh config/server.properties &
停止 Kafka server :
$ bin/kafka-server-stop.sh
2、单 broker 测试
2.1 新建一个TOPIC(replication-factor=num of brokers)
$ kafka-topics.sh --create --topic test --replication-factor 1 --partitions 1 --zookeeper localhost:2181
2.2 查看topic
$ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
$ ./bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test #查看test topic的情况
删除topic
./bin/kafka-topics.sh --delete --topic test --zookeeper hd1:2181
2.3 在启动 kafka-server 之后启动,运行producer:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
2.4 在另一个终端运行 consumer:
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
在 producer 端输入字符串并回车,查看 consumer 端是否显示。
3、多 broker,即Kafka集群配置 测试
2)配置$KAFKA_HOME/config/server.properties
我们安装3个broker,分别在3个vm上:zk1,zk2,zk3:
zk1:
$ vi $KAFKA_HOME/config/server.properties
broker.id=0
port=9092
host.name=zk1
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zk2:
broker.id=1
port=9092
host.name=zk2
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
zk3:
broker.id=2
port=9092
host.name=zk3
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
3)启动zookeeper服务, 在zk1,zk2,zk3上分别运行:
$ zkServer.sh start
4)启动kafka服务, 在zk1,zk2,zk3上分别运行:
$ kafka-server-start.sh ../config/server.properties
5) 新建一个TOPIC(replication-factor=num of brokers)
$ kafka-topics.sh --create --topic test --replication-factor 3 --partitions 2 --zookeeper zk1:2181
6)假设我们在zk2上,开一个终端,发送消息至kafka(zk2模拟producer)
$ kafka-console-producer.sh --broker-list zk1:9092 --sync --topic test
在发送消息的终端输入:Hello Kafka
7)假设我们在zk3上,开一个终端,显示消息的消费(zk3模拟consumer)
$ kafka-console-consumer.sh --zookeeper zk1:2181 --topic test --from-beginning
将日志推送到 kafka
例如,将 apache 或者 nginx 或者 tomcat 等产生的日志 push 到 kafka,只需要执行下面代码即可:
$ tail -n 0 -f /var/log/nginx/access.log | bin/kafka-console-producer.sh --broker-list localhost:9092,localhost:9093,localhost:9094 --sync --topic zerg.hydra

