1、推荐算法的条件
推荐算法从92年开始,发展到现在也有20年了,当然,也出了各种各样的推荐算法,但是不管怎么样,都绕不开几个条件,这是推荐的基本条件
- 根据和你共同喜好的人来给你推荐
- 根据你喜欢的物品找出和它相似的来给你推荐
- 根据你给出的关键字来给你推荐,这实际上就退化成搜索算法了
- 根据上面的几种条件组合起来给你推荐
实际上,现有的条件就这些啦,至于怎么发挥这些条件就是八仙过海各显神通了,这么多年沉淀了一些好的算法,今天这篇文章要讲的基于用户的协同过滤算法就是 其中的一个,这也是最早出现的推荐算法,并且发展到今天,基本思想没有什么变化,无非就是在处理速度上,计算相似度的算法上出现了一些差别而已。
2、推荐系统的算法
按照使用的数据,主要分为以下三种算法:
− 协同过滤推荐(Collaborative Filtering, 简称CF):基于用户的协同过滤(User-based),基于物品的协同过滤(Item-based),基于模型的协同过滤;
− 基于内容推荐(Content-based ):用户内容属性和物品内容属性;
− 社会化过滤:用户之间的社交网络关系,如朋友、关注关系等。
按照模型划分,主要有以下三种:
− 最近邻方法(k-Nearest Neighbor,简称kNN):基于用户/物品的协同过滤算法;
− Latent Factor Model:基于矩阵分解的模型;
− 图模型:二分图模型,社会网络图模型等。
3、协同过滤(CF)
要理解什么是协同过滤 ,首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐, 而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤推荐,是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。协同过滤最大优 点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。
要实现协同过滤,需要一下几个步骤
- 收集用户偏好
- 找到相似的用户或物品
- 计算推荐
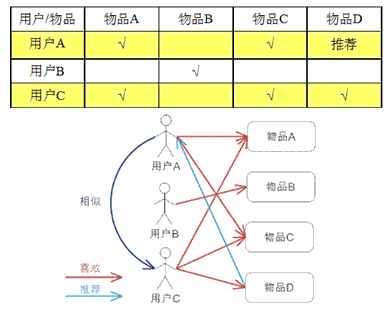
基于用户的CF:推荐和你有相似爱好的其他的用户的物品,与之对应的是基于物品的推荐算法,推荐你喜欢物品的相似物品。
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量 来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。 下图给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
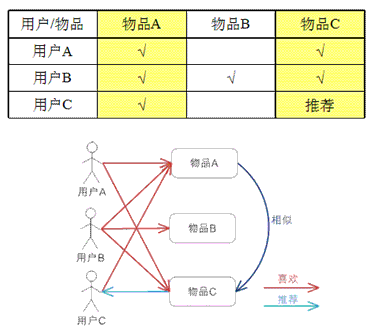
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算 的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的 物品,计算得到一个排序的物品列表作为推荐。下图给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
4、基于内容推荐(Content-based )
基于内容的推荐,是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。 基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。
基于内容推荐方法的优点是:
(1)不需要其它用户的数据,没有冷开始问题和稀疏问题。
(2)能为具有特殊兴趣爱好的用户进行推荐。
(3)能推荐新的或不是很流行的项目,没有新项目问题。
(4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。
(5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。
缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。
七、主要推荐方法的对比
各种推荐方法都有其各自的优点和缺点,见表1。
| 推荐方法 | 优点 | 缺点 |
| 基于内容推荐 | 推荐结果直观,容易解释; 不需要领域知识 | 稀疏问题;新用户问题; 复杂属性不好处理; 要有足够数据构造分类器 |
| 协同过滤推荐 | 新异兴趣发现、不需要领域知识; 随着时间推移性能提高; 推荐个性化、自动化程度高; 能处理复杂的非结构化对象 | 稀疏问题; 可扩展性问题; 新用户问题; 质量取决于历史数据集; 系统开始时推荐质量差; |
| 基于规则推荐 | 能发现新兴趣点; 不要领域知识 | 规则抽取难、耗时; 产品名同义性问题; 个性化程度低; |
| 基于效用推荐 | 无冷开始和稀疏问题; 对用户偏好变化敏感; 能考虑非产品特性 | 用户必须输入效用函数; 推荐是静态的,灵活性差; 属性重叠问题; |
| 基于知识推荐 | 能把用户需求映射到产品上; 能考虑非产品属性 | 知识难获得; 推荐是静态的 |
一般来说基于用户行为的协同过滤方法要优于基于内容的技术,但会有冷启动的问题。对于新系统来说,基于内容的推荐则更优。
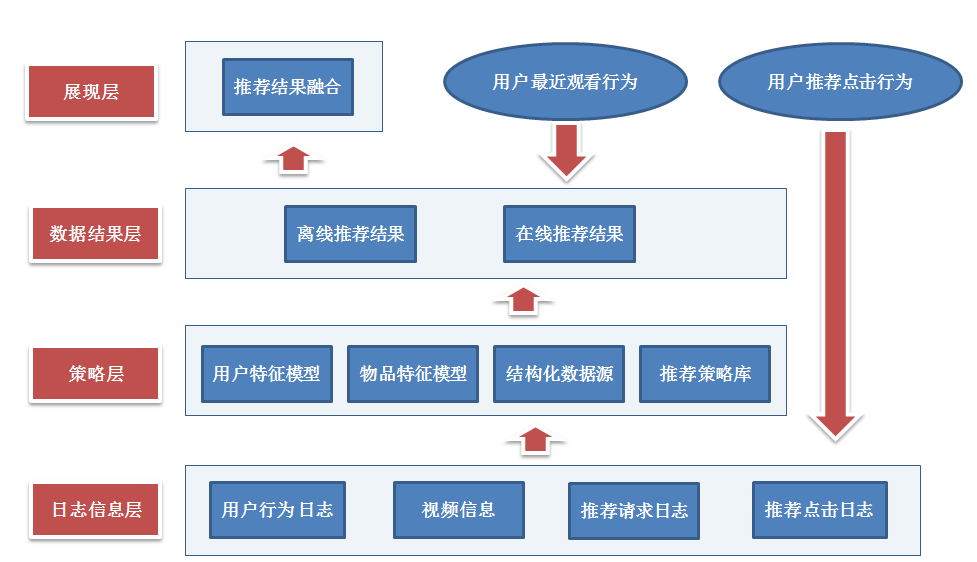
架构
主流的推荐系统的架构如下图:
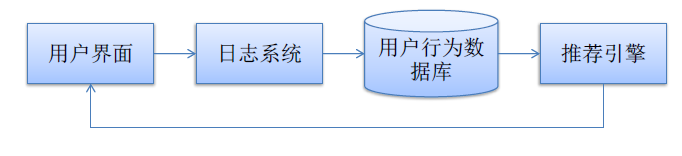
而动态推荐系统的架构如下:
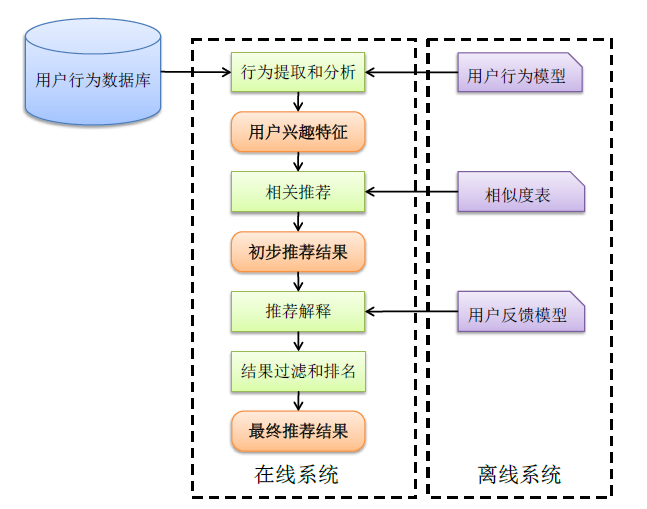
上图中,推荐引擎的构建来源于不同的数据源(也就是用户的特征有很多种类,例如统计的、行为的、主题的)+不同的推荐模型算法,推荐引擎的架构可以试多样化的(实时推荐的+离线推荐的),然后融合推荐结果(人工规则+模型结果),融合方式多样的,有线性加权的或者切换式的等
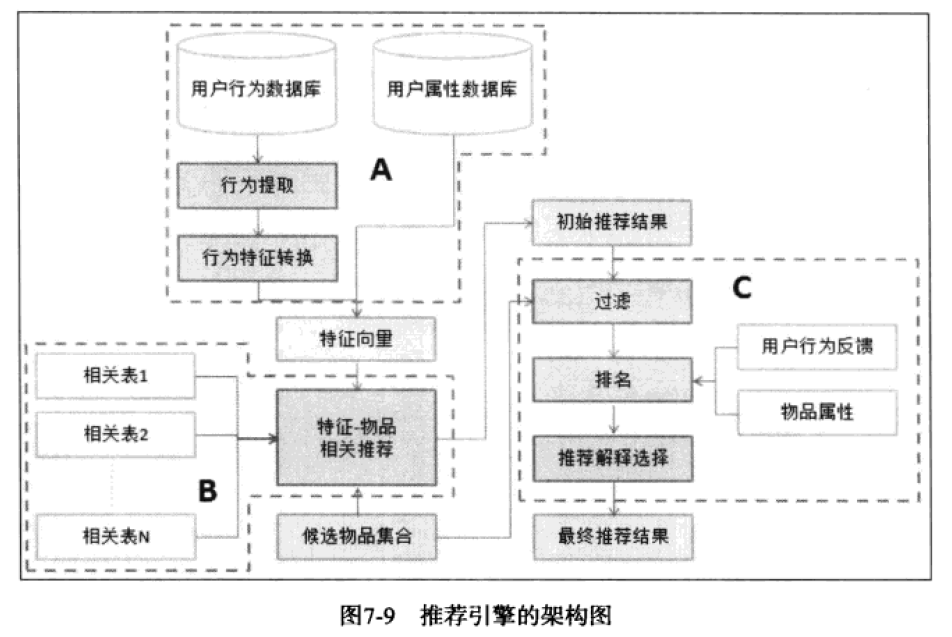
优酷的推荐系统