

一、在现实生活中,一个目标变量(y)可以认为是由多个特征变量(x)影响和控制的,那么这些特征变量的量纲和数值的量级就会不一样,比如x1 = 10000,x2 = 1,x3 = 0.5 可以很明显的看出特征x1和x2、x3存在量纲的差距;x1对目标变量的影响程度将会比x2、x3对目标变量的影响程度要大(可以这样认为目标变量由x1掌控,x2,x3影响较小,一旦x1的值出现问题,将直接的影响到目标变量的预测,把目标变量的预测值由x1独揽大权,会存在高风险的预测)而通过标准化处理,可以使得不同的特征变量具有相同的尺度(也就是说将特征的值控制在某个范围内),这样目标变量就可以由多个相同尺寸的特征变量进行控制,这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了。比如在训练神经网络的过程中,通过将数据标准化,能够加速权重参数的收敛。 简而言之:对数据标准化的目的是消除特征之间的差异性,便于特征一心一意学习权重。
二、例子讲解
假定为了预测房子价格,自变量为面积,房间数两个,因变量为房价,那么可以得到的公式为:,其中x1代表房间数,x2代表面积,首先给出两张图代表数据是否均一化的最优解寻解过程
未归一化:
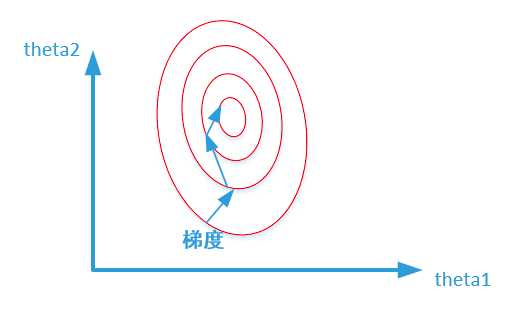
归一化之后:
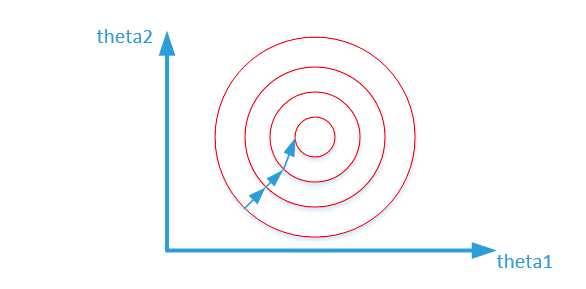
寻找最优解也就是寻找使得损失函数值最小的theta1、theta2。上述两幅图代表的是损失函数的等高线。当数据没有归一化的时候,面积数的范围可以从0-1000,房间数的范围一般为0-10,可以看出面积数的取值范围远大于房间数
形成的影响就是在形成损失函数的时候,数据没有归一化的表达式可以为:J=(3θ1+600θ2−y)2 , 造成图像的等高线为类似的椭圆形状
而数据归一化后,损失函数的表达式可以表示为:j=(0.5θ1+0.55θ2−y)2,其中变量的前面系数都在【0-1】范围之间, 则图像的等高线为类似的圆形形状,
从上面可以看出,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解