

sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类、回归、降维以及聚类;还包含了监督学习、非监督学习、数据变换三大模块。sklearn拥有完善的文档,使得它具有了上手容易的优势;并它内置了大量的数据集,节省了获取和整理数据集的时间。因而,使其成为了广泛应用的重要的机器学习库。下面简单介绍一下sklearn下的常用方法。
1. 监督学习
sklearn.neighbors #近邻算法 sklearn.svm #支持向量机 sklearn.kernel_ridge #核-岭回归 sklearn.discriminant_analysis #判别分析 sklearn.linear_model #广义线性模型 sklearn.ensemble #集成学习 sklearn.tree #决策树 sklearn.naive_bayes #朴素贝叶斯 sklearn.cross_decomposition #交叉分解 sklearn.gaussian_process #高斯过程 sklearn.neural_network #神经网络 sklearn.calibration #概率校准 sklearn.isotonic #保守回归 sklearn.feature_selection #特征选择 sklearn.multiclass #多类多标签算法
2. 无监督学习
sklearn.decomposition #矩阵因子分解 sklearn.cluster # 聚类 sklearn.manifold # 流形学习 sklearn.mixture # 高斯混合模型 sklearn.neural_network # 无监督神经网络 sklearn.covariance # 协方差估计
3. 数据变换
sklearn.feature_extraction # 特征提取 sklearn.feature_selection # 特征选择 sklearn.preprocessing # 预处理 sklearn.random_projection # 随机投影 sklearn.kernel_approximation # 核逼近
4. 数据集
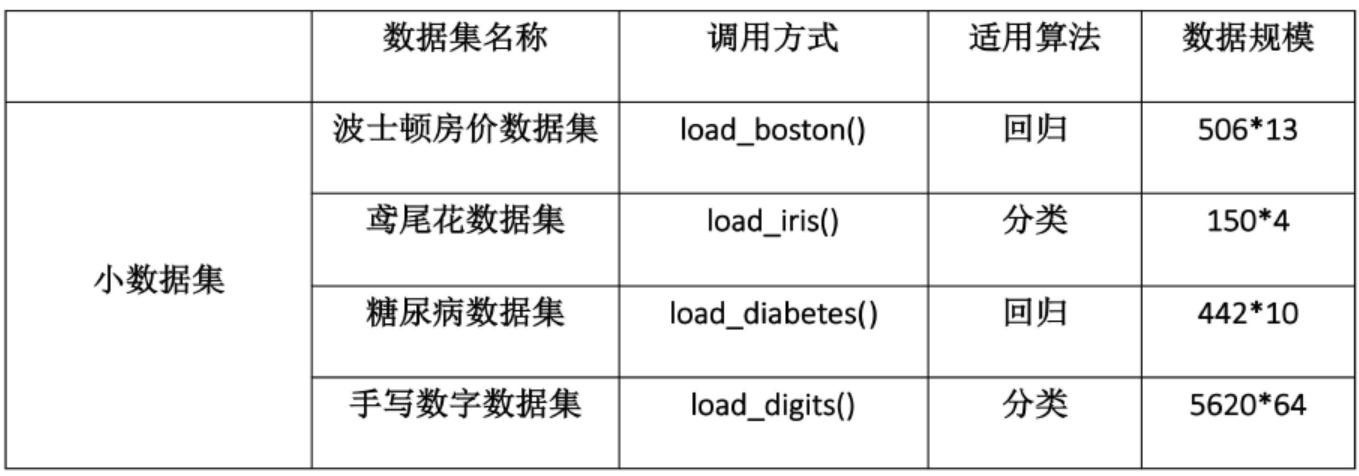
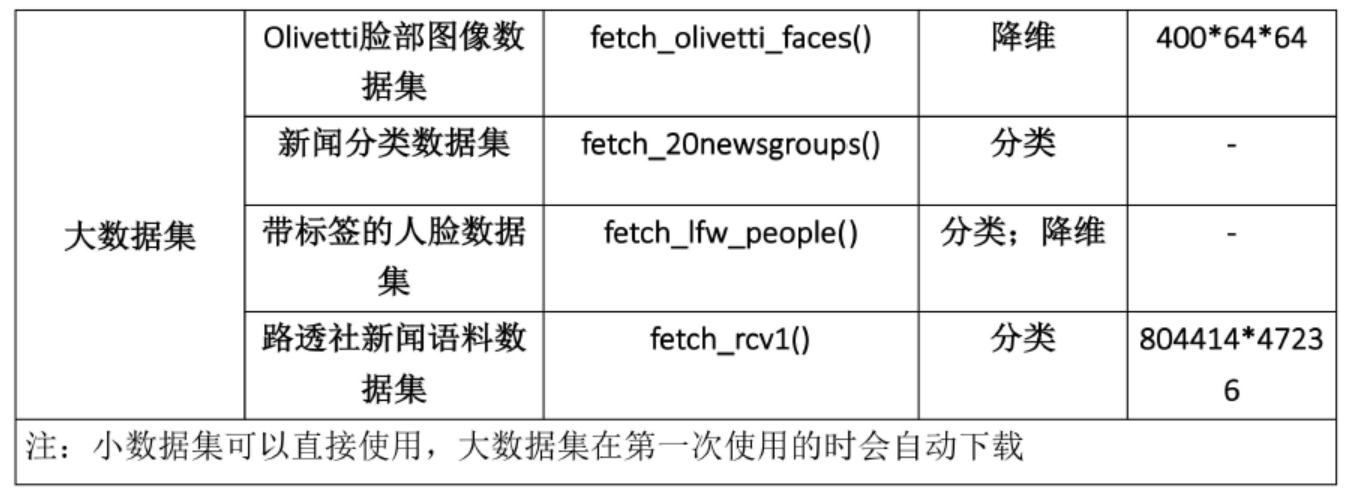
5.开发流程
sklearn一般实现流程:
step1. 数据加载和预处理
step2. 定义分类器, 比如: lr_model = LogisticRegression()
step3. 使用训练集训练模型 : lr_model.fit(X,Y)
step4. 使用训练好的模型进行预测: y_pred = lr_model.predict(X_test)
step5. 对模型进行性能评估:lr_model.score(X_test, y_test)